 �ٷ���
�ٷ�������AI�W������2025�Ɨ�������o�緽����AI�����ۡ��_��������̕r��
�ڽ����e�k��2025�Ɨ�����F�����o�緽���Ƴ��ć�������ڡ��˵��ˌ��r��ģ�B����ģ�͡���AI�W��C���ˡ������࣬�ɞ�ȫ�����c���@��aƷ�ھ��|�A�ۃH�Ͼ�һ�ܣ��N����ͻ����10000�_���@�����ֲ��H�w�F���Ј������|AI��̮aƷ�Ŀ��������Aʾ����ģ�B��ģ�������M��Ӳ���I����̘I��������ڵ�����
����һλ�F���������f����̫���ˣ��K�ڲ�ֹ��AI����ˣ����ǽ�Q�˺ܶ����ʹ�c���}������AI���g�������Ľ��죬����ijɹ����S��C�ˣ������ِ�����������ӡ��ȡ�������������Ј��I�Ρ������˲�Ŀ���ǣ�������չ�����g���F���@�����ϰ�λ���L���A����ͬ�r�����ˎ�ʮ��AI�aƷ���m���ӟo�緽��EVAģ�͵ĺ����C�����ɞ鱾�ô������̘I������AIӲ���aƷ��

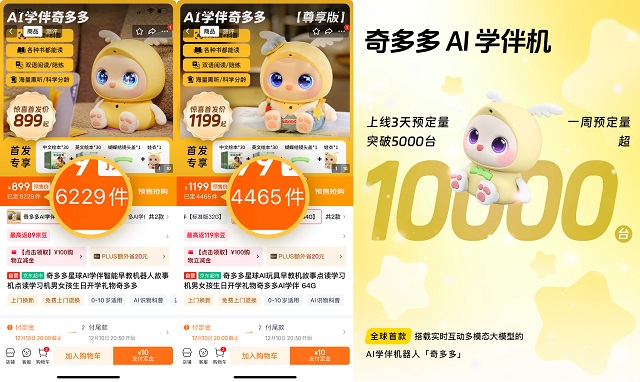
�Ɨ�����F���𱬣�����չ�F�挍��
���Ɨ����3̖�^��ǰ�ؑ����^��������չ�_�����������˴�����չ�^���������v���w���ӂ������L������������ߡ��L����Ʒ�ȣ��c�����M����Ȼ���ӣ��F����՟��ҡ�

����չ�F���IJ��H�H���Z���������������������Ķ�ģ�B�������������܉��R�e�������е������L��/�̲�/��Ƭ���x��oՓ���ġ�Ӣ�ģ�������ͯ�x����s��ɢ�Ļ���Ű棬���ܾ����R�e�����ܿ������ӵĬF���L�������܌��ճ���Ʒ�M�м��r��Ȥ�Ŀ��գ�����W�ĿƌWԭ�����Ժ����܉�������Z�����������Ϻ��ӡ�߅����߅����߅�W���ĿƌW�����·��
չ��������r�g�����չʾ�������@�@����x�������������Е��������R�e�⣬߀�ṩ�����N��xģʽ��
���xģʽ�����R�e������͵��x���N�����Z�����֣��Z�����б��F��������Cе�У�
���gģʽ��֧�ֶ��Z�Լ��r���g���xһ��Ӣ�ġ����gһ�����ģ��������dȤ��xȫӢ�IJ��ϣ�
ָ�xģʽ�����֡����~���D�������R�e�����o�����P���գ�������y�c�x�P���~��P��
���@��ζ�����L������Ҫُ�I�c�x�P���~��P�����C�ȶ�N�aƷ����һλ�F�������u�r����һ�C��Q������x�������������x�n�����͌WУ�n�I�Y�ϣ��@���������Ľ�Q���衣��

���c���yAI�aƷ�Ľ�����ͬ�������Ҫ�������ջ���Ԓ��Ҳ����Ҫ�ȴ����L��푑��r�g����ע�����D�ơ����o�緽��CPO��N��С�̣��ڬF����B�������ӂ����Ը���Ȼ��߅����߅����߅�W���@�Ƿ��σ�ͯ�J֪�О�ĸ�����ͻ�ơ���

ͻ���Թ��ܣ��ġ�AI��顱�������ܝM�㡱���|׃
�A�����f�����྿��������ʲô��
С�̱�ʾ�������ȷdz����x�V���Ñ������ϲ�ۺ��J�ɡ������ͻ����Ҫ���ڃɷ��棺һ�����ǻؚw��һ��ԭ��������̮aƷ����������ھ���һ�������҂����е�EVA���r��ģ�B����ģ�ͣ��������M��aƷ����
�ć��Ȏׂ��������ƽ�_����؛�ʔ�����֪����̮aƷ��؛�ʸ��_30%-70%��������؛��ƫ�͵��ǹ��C��Ѭ �C�@aƷ��AIaƷ����؛���Ƿdz��ߵġ��������Ӳ�������Ǽt��ِ�������H�aƷ���ϲ��]�НM����L�͌�ؐ��������

�����ͻ���Թ�����Ҫ�w�F�������棺
1.�ܡ�����������۾���AI�R������cȫ����x
�o�緽�ۄ�ʼ��&CEO���Ԗ|��ʿָ��������Ҋ�ġ��Z��AI+CVҕ�Xģ�͡����挍���g�����Е�������ʧЧ�����w���F�飬��Ҋ�ă�ͯ�Z���R�e�e�`�ʸ��_52%��������������R�e�ʴ_�ʲ���35%������Ҋ��Ʒ�`�R�ʳ�40%�����s�������h���J֪ˮƽ����
EVAͨ�^��ģ�B�И�+���L���J֪���桱�ܘ����Fͻ�ƣ��ġ������m�䡱������ͯ�Ѻá�������ҕ�X���������֧�Σ�
��ͨҕ�X���⡾�ۡ�����ͯ��߅��߅�����Ǻ��Ľ������T����AI�Z���⣬�������ҕ�X�R�e�����������o����֪�R������չ���������ճ���Ʒ��Ϳ�f��Ʒ���WУ�l�Ī��Ʒ�ȣ��@Щ����ϲ�gչʾ���ᆖ���������������R�e��
��AIҕ�X�R��Ϳ����⣬����߀�Џ������x������֧�ֲ�ͬ���w�����Z�ԡ�ȫ����x����R�e����ؐ������L�����������n�����ڿ�����Ƭȫ���R�e����x���ṩ3�N��xģʽ�����x�����g��ָ�x����Ч����c�x�P���~��P�ȮaƷ��

2.�������˵ĵ����t�����ٶ�
�������t�˜ʡ��졿���Z���������t��250ms��ƥ�����ע�����D�����ԣ���ҕ�l�������t��400ms�������R�e/�����R�e���t��300ms������߅����ҕ�X���������㷨��֧�ּ��r����������ʹ������Ӳ���O�����ܣ�Ҳ���Կ������뼉푑���

0-10�q��ͯ��ע�������m�r�g�H��10-30��犣����^1���푑����t�͕��Д�ע��������ȱ��ҕ�X����Č��r���ӄt���Дࡰ�Ŀ����W���ĺ����·���ܶ�AI�Z���aƷ���ð���ʽ������������6�����ϣ������ǟo������ʹ�õġ�
�����ӆ����@��ʲô���r������ȴ����^1�룬������ע�����Ϳ����D�ơ���С�̽�ጵ������҂��ļ��g�Fꠞ���M���˴����������_�������^����Ȼ�B؞����

3.�ܡ����L���Ă��Ի�����
����c���L�wϵ���顿���߂�48�N��wӋ���wϵ��100+�N������黥�ӣ��ɿ�¡��ĸ����ɫ�c���ӌ�Ԓ�����Ђ��Ի�ӛ�����控��AI���L�wʹÿ�����Ӷ��Ќ������Լ������ࡣ
�����ǎ��г��L���Ե�AI�aƷ�����S���Ñ���ʹ�ã����Ի��m���Ñ���ӛ���Ñ�����Ҫ�¼���ÿ�����ӓ��Ќ����Լ������ࡣ�䱳����P�I�ǡ��惦��ӛ�� + ������ӛ�����ļ��g�Y�ϣ��錚ؐ�����쌣�ٵ� ��ӛ�����桱��

���g�Ⱥˣ�EVA��ģ�����ͻ���ИIƿ�i
���Ԗ|��ʿ��������˱���ļ��gԭ�����������҂���Ҫ����һ���O���Č��r��ģ�B��ģ�́��x��Ӳ�������˰�Ľ���������ģ�Bģ�������܉��ں��ı����D�����l�ȶ�N��Ϣ�ΑB���ṩ�����ܡ��M�˻��Ľ��������ɞ���Ҫ�о������҂���ȥ����������ز����@�������ژI��]���κάF���_Դ��������r�£�������ȥ��8�·��Ƴ��ˇ���SOTA��EVA�˵��˶�ģ�Bģ�ͣ����Ƚ�Q�˶�ģ�B�̘I������ƿ�i����AI�����x���ˡ������й١��c������X�������a������������ص����һ�����
�ڴ˻��A�ϣ�EVA���������˃�ͯ��̈��������ģ���m�䡣���e���ǿ������f���c��������ҕ�Xħ������AI�R������cAI���Е�ȫ���x��

��̈���ҕ�X�R�e���R�Ĵ�������𣬰����ǘ˜ʕ����������Ű桢�����w�ȣ��������ΑB��׃�����s�h���ɔ_�Լ���ͯ�ǘ˜ʕ�����Ϳ�f����ͨAI�R�e�ʴ_�ʵ���30%����������ʳ�45%���y�ԝM�ヺͯ�W������
EVAᘌ���̈����M����ȫ��Ĉ�����ҕ�X�����������䡰����ȫ���R�e���桱֧������e��������������ͨ�^���w�Uչ���Ű������ӡˢ�������F96%�Ĝʴ_�ʣ�����ͬ���Z�����x�c���ջ��ӡ��ڌ����R�e���棬����С�ӱ��W�����g���H��3-5���ӱ������R�e����Y�϶�ģ�B���պͿ��ɔ_�������ڏ��s�h�����Ա���93%���Ϝʴ_�ʡ�ᘌ���ͯ����Ϳ�f��EVAͨ�^����Ӗ����������ģ�̓��������F94%�����I�R�e�ʴ_�ʣ����܌��ǘ˜ʕ������������ԣ�߀�Ɍ�Ϳ�f�P���Ճ��ݼ��l�����dȤ��

���Ի��c�[˽���o������ƽ��
�ڂ��Ի����棬С�̽�B����AI���aƷ��ֻ�����Â��Ի����L�r����������ʹ�Õr�L�ͻ��S�ȡ������ǎ��г��L���Ե�AI�aƷ�����S���Ñ���ʹ�ã����Ի��m���Ñ���ӛ���Ñ�����Ҫ�¼���ÿ�����ӓ��Ќ����Լ������ࡣ�䱳����P�I�ǡ��惦��ӛ��+������ӛ�����ļ��g�Y�ϣ��錚ؐ�����쌣�ٵġ�ӛ�����桯����

�@��Ҫ��������ģ�K�fͬ�������J֪ӛ��ģ�K��ۙ���ӵ�֪�R܉�E���������J֪�˺������ӛ��ģ�K�t���ػ��惦���ӵĂ���ƫ�ã�����ӛ��ģ�K���������e��˹�z�������ӑB�{��ӛ�����ݵă��ȼ���
ᘌ����L�P�ĵ��[˽��ȫ���}�����Ԗ|��ʿ���{�����@���҂��O����ҕ���P�I���}���҂�ͨ�^���Ӽ��g���ϡ����Ƶļ��L���ƹ��ܡ����Ĕ������Z�Լ���Ҏ���OӋ��ȫ���������L�������[˽��]����
���҂������Ե��аlPrivateLoRA���g���Mһ���ӏ���ͯ��Ϣ�İ�ȫ�c�[˽���o��EVA����PrivateLoRA������һ���[˽���ȵĴ�ģ�ͼܘ��������˼·�nj��漰�Ñ��[˽��Ӌ���΄ձ��ػ������w�������˽K���O����С�ԓ���g���������m�䣨LoRA�����������{��ģ�͕r�HӖ�����������������o��ԭʼ�����ς����ƶˣ��Ƚ����˔�����ݔ�е�й¶�L�U��Ҳ���ñ����������F��Ȃ��Ի�̎������ԓ���g�҂������g��^�_Դ��https://wanglamao.github.io/�������Ƅ��[˽���o��ģ�͵İlչؕ�I������

�_�����B��EVA OSÿ��Ӳ�������С�ҕ�X�ǻ۴��X��
���Ԗ|��ʿ������EVA OS��δ���_��Ӌ�����������f��EVA OS����������ĵġ��۾����͡����X��������һ���˜ʻ����ɲ�ε�ܛӲ��һ�w���������κ���������Ӳ���Ĺ�˾���o����^�аlAI��ֱ��ʹ���҂����аl�����ɡ���
EVA OS��Ҫ�_�������������ģ�B����API��֪�R�cҕ�X�ӿڡ�Ӳ���m��SDK�Լ��V����Ӳ�������ԡ��������������ȡ���@����Ч��ij֪����ͯ���������EVA�����R�e��������С�����Օ����Ñ���x�r�L����3.5����������ߏS��ͨ�^�����R�eAPI��ʹ���h�R�aƷ���ӡ��R�e����/�B��Ŀ��չ��ܣ��N�����L52%��
δ����EVA OS�����ڴ���һ���_�š��fͬ�����B�����H�ṩ���g�ӿڣ���ͨ�^�_�l����^��Ԕ�M���ęn�ͼ��g֧�֣����m�x�ܺ�����飬��ͬ�ƄӶ�ģ�BAI������Ӳ���I��Ą����c���á�
�҂�ϣ�����������ߣ��Ƽ�ƽ���ˣ����F�Ƽ��ջݡ��ИI���s��

؟�ξ���kj005




��Ҷ��ڿ�



�ذ����]

Ӣ�ؠ��ӡ����� AI ���������Ӹ�УӋ������У�@����һ�I�_��

�c�ഺ�Ĺ��Q�����ٿ�У�@AI��У�С�25���_�W���A�M��Ļ

�Ĕ������������ܑ��ã�ϣ������JDD 2025����̽AI�a�I��·��

2025늲��������_��AI֮�۽��iȫ�����ǻ�����

���ٔ������ĸ��|�����O ���AAI�r��

����Ŵ��졸�m�л����N����������ħ��S2Ultra���iAI����ȫ���w�

AI�������أ��������{����ȫ���´�ِ

2025���|��ȫ���»����¡���e�� AI�����Ӯa�I�|׃�S�w